Latent-Variable PCFG Viewer
Latent-variable probabilistic context-free grammars are a generative grammar model with various applications, most prominently for learning and parsing with phrase-structure trees. The model was introduced independently by Matsuzaki et al. (2005) and Prescher (2005), but it also has strong relationship to regular tree grammars, which have been known for a while. For an overview of L-PCFGs, their uses and learning algorithms see Cohen (2017).
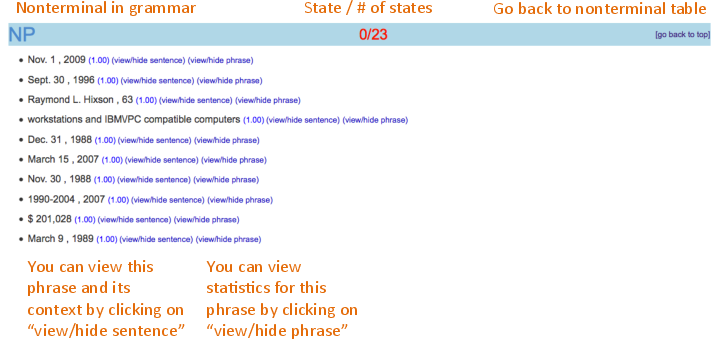
L-PCFGs are just PCFGs where the nonterminals and preterminals in the grammar are added latent information: a state that refines their syntactic categories. This means that now, in the grammar, instead of having just the nonterminal NP, we might have NP-1, NP-2, etc., denoting different types of noun phrases. The probability of a tree with latent states remains the product of all rule probabilities with the latent states. However, the learning problem with L-PCFGs usually assumes that the latent states are not observed -- only the coarse basic categories are observed.
Traditional estimation of L-PCFGs is done through the use of the expectation-maximization algorithm and derivatives of it (Matsuzaki et al., 2005; Petrov et al., 2006). More recently, four new algorithms have been introduced for estimating L-PCFGs (Cohen et al., 2012; Cohen and Collins, 2014; Narayan and Cohen, 2015; Louis and Cohen, 2015; Narayan and Cohen, 2016). These so-called spectral algorithms use singular value decomposition as a technique for dimensionality reduction of feature vectors that indicate the latent states.
We hope that our viewer will enable curious researchers to compare and contrast the different representations and grammars learned with the spectral algorithms and more traditional algorithms such expectation-maximization. It enables to do that for a group of languages, including Basque, English, French, German, Hebrew, Hungarian, Korean, Polish and Swedish.
The database of this viewer includes the training sets of various phrase-structure treebanks, on which an L-PCFG grammar model was applied to find for each node in each tree in the training set the most likely latent state. As such, it associates nonterminals and latent states with phrases.
Here is the viewer's interface:
Back to main page
Developed by Shashi Narayan and Shay Cohen (April 2016)
Acknowledgements: Mark Steedman, Shalom Lappin and members of CLASP
Parse tree visualization using parseviz.